However, the square of the vertical distance is only one of many reasonable ways of measuring the distance from the data points to the line mx + b. For example, it is perfectly reasonable to consider instead the expression 1 + (mxi + b - yi)2. If (xi, yi) is on the line, this value would be equal to 1, and its logarithm would then be zero. Thus, the function
There is a priori no particular reason to prefer one error function over another. And for each choice of such we could end up with a problem whose solution exists and produces a line that best fit the data. Then we could compute the value of the error function for the best fit line, value that depends upon the choice of function made. A canonical way of choosing the best error function could be that for which this number is the smallest. But finding such a function is quite a difficult, if not impossible, problem to solve. If we limit our attention to linear estimators, in a sense to be explained in the last section of this chapter, the solution obtained in §3 is optimal. In here, we pursue further the problem of finding the best fit according to the two error functions introduced above.
Notice that if
![]() = mxi + b - yi, data with large
errors
= mxi + b - yi, data with large
errors
![]() excert a huge influence on the original error function
of §3 (because we use
excert a huge influence on the original error function
of §3 (because we use
![]()
![]() ). The two error
functions mentioned above grow linearly (or sub-linearly)
with
|
). The two error
functions mentioned above grow linearly (or sub-linearly)
with
|![]() |, causing the tails to count much less heavily. We will
see this when comparing the different results.
|, causing the tails to count much less heavily. We will
see this when comparing the different results.
In order to solve the problem now at hand, we first generate some ``noisy''
data. We load the routines in lsq_data.txt:
>
read(`lsq_data.txt`);
![]()
The data and its graphical visualization can then be obtained by:
>
pts:=bad_line_pts():
>
plot(pts,style=point,symbol=box);
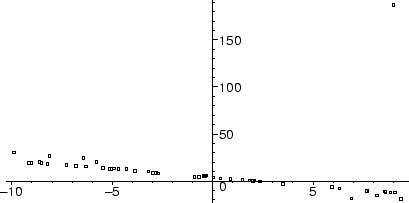
You should notice that while most of the data lies fairly near a line, there is one point which is extremely far away from the rest of the data.
In order to compare results, let us first find the line given by least
squares. First, we define a function ![]() , which gives the signed
vertical distance between a point pt and a line of slope
m and intercept b
, which gives the signed
vertical distance between a point pt and a line of slope
m and intercept b
>
epsilon:= (pt,m,b) -> (m*pt[1]+b-pt[2]);
![]()
Now we compute the regular least squares fit.
>
H:=(m,b,pts)->sum(epsilon(pts[i],m,b))^2,i=1..nops(pts)):
sol:=solve(diff(H(m,b,pts),m)=0, diff(H(m,b,pts),b)=0,m,b);
![]()
>
display(plot(pts,style=point,symbol=box),plot(subs(sol,m*x+b),x=-10..10),
view=-20..20);
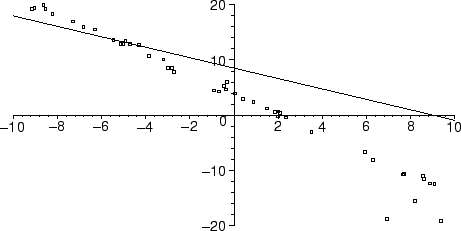
In the above, we restricted our attention to the region -20 < y < 20, where the line and the majority of the data lies. As you can see, the fit to the majority of the data is very poor, because of the influence exerted by the anomalous data point.
Now, let's try again, this time minimizing
ln(1 + ![]() /2),
which behaves like
/2),
which behaves like
![]() for small errors, but grows very
slowly for large ones.
for small errors, but grows very
slowly for large ones.
>
R:=(m,b,pts)->sum(ln(1+epsilon(pts[i],m,b)^2/2),i=1..nops(pts));
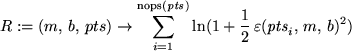
Here's what the functional we want to minimize looks like:
>
plot3d(R(m,b,pts),m=-5..0,b=-20..0,style=patchcontour, axes=boxed);
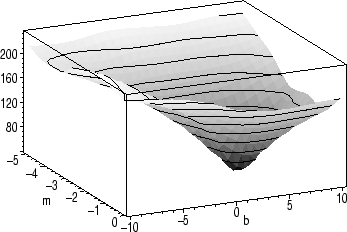
The equations we want to solve are not linear. In fact, they're messy enough that Maple needs some help to find the minimum. By examining the plot and zooming in on the minimum, we can choose an appropriate region.
>
plot3d(R(m,b,pts),m=-2..-1.5,b=3..5,view=38..50, axes=boxed);
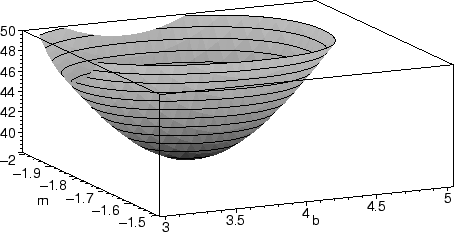
Once we have an appropriate region, we can ask Maple to look for the solution numerically using fsolve.
>
rs:=fsolve( diff(R(m,b,pts),m)=0, diff(R(m,b,pts),b)=0,
m,b,m=-2..-1.5, b=3..5);
![]()
And here we can compare the two lines found.
>
p := plot(pts,style=point):
l := plot(subs(sol,m*x+b),x=-10..10):
s := plot(subs(rs,m*x+b),x=-10..10,color=blue):
plots[display](p,l,s,view=-20..20);
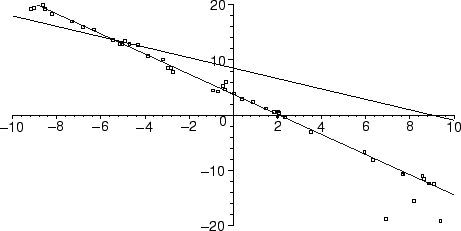
Let us now try to minimize
![]() |
|![]() |. Since this function is
not even differentiable near
|. Since this function is
not even differentiable near
![]() = 0, we have to work harder
to get less.
= 0, we have to work harder
to get less.
>
A:=(m,b,pts)->sum(abs(epsilon(pts[i],m,b)),i=1..nops(pts));
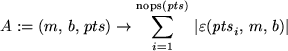
Displaying the graph of this function gives us an idea about where its
minimum lies:
>
plot3d(A(m,b,pts),m=-5..0,b=-10..10,style=patchcontour, axes=boxed);
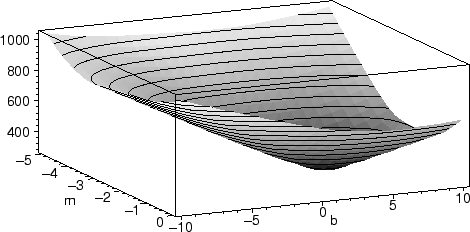
>
plot3d(A(m,b,pts),m=-1.0875..-1.0872,b=3.817..3.8178, axes=boxed);
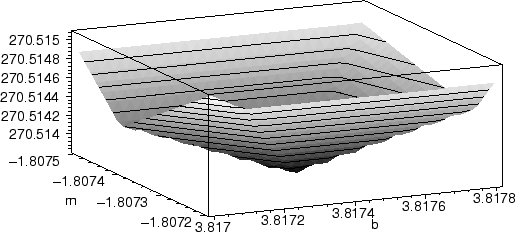
This leads us to a choice of m = - 1.80733, b = 3.8174 as our ``best'' line. This is almost (but not quite) the same line found using our distance R(m, b).